
Bases de datos para deep y machine learning

Los sistemas inteligentes, así como las redes neuronales, basan su efectividad en la información con la cual se les alimente, por ejemplo, un algoritmo de red neuronal, puede ser el más rápido en aprender y el mejor en hacerlo, pero si no tiene suficientes datos de entrada, este no va a tener puntos de referencia para aprender, ya sea de forma supervisada o no supervisada, y por lo tanto, el resultado de la ejecución del algoritmo será limitado, dicho en otras palabras, será un modelo “tonto”.
Es bien sabido que una rede neuronal “aprende” en base a los casos con los cuales se le entrena, y entre más casos sean introducidos en su aprendizaje, mayor será la “inteligencia” que desarrolle; pero no sólo el número de casos es un factor relevante, estos casos también deben de estar colocados a lo largo de todo el universo de información relacionado al fenómeno a modelar y no sólo en pequeñas secciones de este. Es precisamente debido a estas situaciones que se tiene la necesidad de poder entrenar a nuestras redes neuronales con bases de datos apropiadas y del tamaño suficiente para poder generar un modelo apropiado del fenómeno a caracterizar.
En internet existen una gran cantidad de bases de datos que se pueden consultar y utilizar de forma libre (Obviamente, citando la fuente) para el desarrollo de experimentos científicos, académicos y de toda índole Las cuales ya han sido probadas, y son mejoradas con el paso del tiempo. Estas bases de datos son el esfuerzo de muchos individuos, grupos de personas, instituciones académicas, instituciones gubernamentales, e incluso instituciones privadas que las han desarrollado y las han colocado en una página web, esperando que los desarrolladores las utilicen y puedan generar conocimiento de frontera y/o que puedan generar modelos de comportamientos de cualquier fenómeno, como por ejemplo, la percepción popular de las diferentes vacunas contra el Covid-19 (https://www.kaggle.com/datasciencetool/covid19-vaccine-tweets-with-sentiment-annotation ).
En esta sección, vamos a describir algunas de ellas, esperando que el alumnado, y cualquier interesado, pueda sacar provecho del conocimiento que se transmite de forma libre y gratuita por Internet.
Kaggle
Este sitio es un repositorio con una gran cantidad de datasets enfocados al análisis por medio de machine learning y Deep learning. Dentro de las descripciones de los conjuntos de datos se encuentran códigos realizados por los usuarios para mostrar el tratamiento y diferentes aplicaciones de cada una de las bases de datos, incluyendo aplicaciones en Procesamiento de Lenguaje Natural (PLN), lo que dota a cada uno de estos archivos de un valor agregado para un estudiante o un científico del área. Las bases de datos, se encuentran principalmente en archivos .CSV, lo que le da dinamismo para su uso y transportación. La página es https://www.kaggle.com/
Dentro de las bases de dato de interés dentro de este repositorio se encuentran:
- Tweets sobre las opiniones de las vacunas de Covid -19, https://www.kaggle.com/datasciencetool/covid19-vaccine-tweets-with-sentiment-annotation
- Opiniones en Amazon sobre diferentes productos, etiquetados como opiniones buenas, malas y neutrales, https://www.kaggle.com/kritanjalijain/amazon-reviews
- Clasificación de gestos manuales por medio de movimientos musculares, https://www.kaggle.com/kiatkai96/classify-gestures-by-reading-muscle-activity
UCI Machine Learning Repository

Como su nombre lo indica, este es un repositorio con diferentes datasets que pueden ser utilizados de forma libre, sólo es necesario citar la fuente. Esta página cuenta en su diseño miles de bases de datos de diferentes áreas del conocimiento, tales como ciencias de la vida, Ingeniería, Ciencias sociales, Negocios, Juegos, entre otras. Cada uno de estos archivos cuanta con una descripción detallada de la estructura de la base de datos, las características de los modelos y las clases de los mismos. Este conjunto de información lo puedes encontrar en https://archive.ics.uci.edu/ml/index.php
Algunas bases de datos de interés dentro de este repositorio:
- Utilización de señales EMG para el reconocimiento de gestos manuales, https://archive.ics.uci.edu/ml/datasets/EMG+data+for+gestures
- Reconocimiento de actividad humana por medio del monitoreo del teléfono celular, https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
- Modelado de patrones de usuario dentro dela rede social Facebook, https://archive.ics.uci.edu/ml/datasets/Facebook+Comment+Volume+Dataset
- SPAM dentro de correos electrónicos, https://archive.ics.uci.edu/ml/datasets/Spambase
LabelMe
Este es un proyecto que permite utilizar datasets de diferentes imágenes para poder etiquetar diferentes objetos dentro de ellas. Dentro de la página se encuentra el tutorial para descargar y trabajar con el Toolbox destinado a Matlab. EL proyecto se encuentra en http://labelme.csail.mit.edu/Release3.0/index.php?message=1
Visual Genome
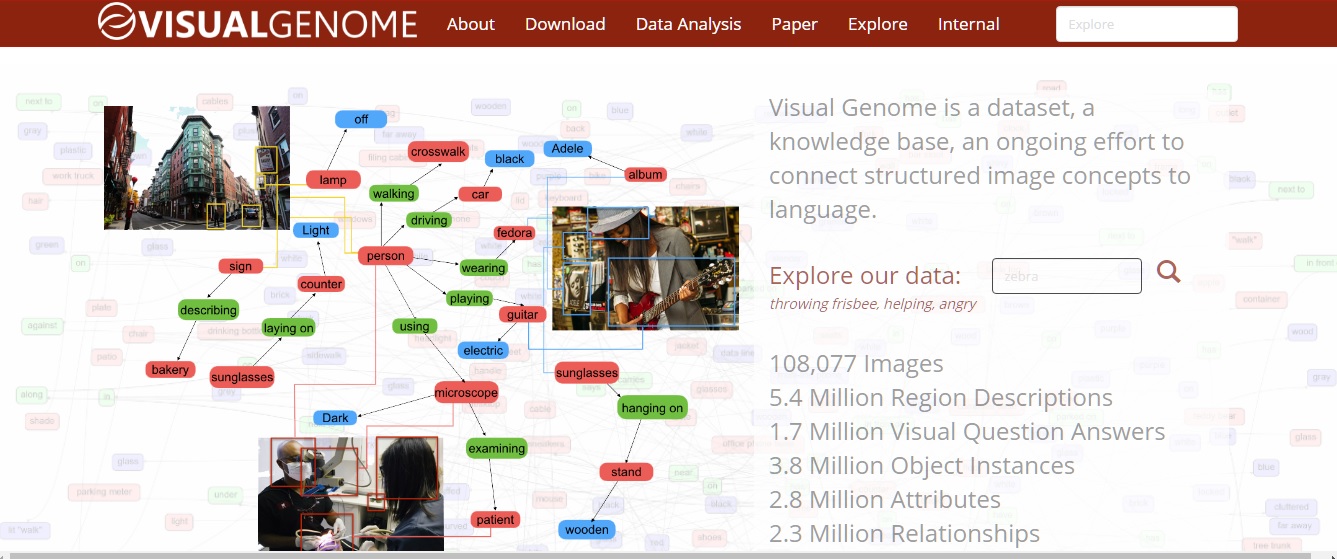
Este proyecto esta destinado a instruir a los usuarios en el etiquetado e identificación de objetos dentro de una imagen, para este fin, la página permite la descarga de miles de imágenes y las descripciones de millones de descripción de regiones, atributos, relaciones, etc. El proyecto se puede ver en http://visualgenome.org/
DATA.GOV
Según la descripción de la mima página “El hogar de los datos abiertos de los Estados Unidos”. Esta página está destinada a almacenar datasets relacionadas a la vida pública (en todos los sectores) de los Estados Unidos de América, se encuentran diferentes temáticas tales como salud humana, medio ambiente, agua, atmosfera, producción alimentaria, entre muchas otras temáticas. Lo interesante de esta página es que son datos recabados por las agencias y departamentos gubernamentales de USA. Los archivos pueden descargarse en diferentes formatos tales como, RDF, JSON, o XML. Estos datos pueden ser consultados en: https://www.data.gov/
Berkeley DeepDrive

Es un dataset destinado al entrenamiento de Inteligencia artificial utilizada en los vehículos autónomos. Este dataset contiene alrededor de 100,000 videos de aproximadamente 1,100 horas de conducción sobre diferentes condiciones, horarios y características de manejo. La base de datos se puede obtener en https://bdd-data.berkeley.edu/
Vissual VQA
Este es un proyecto en demasía interesante ya que permite relacionar preguntas con imágenes, la misma página menciona que las preguntas realizadas requieren un entendimiento de visión, lenguaje y sentido común para poder ser contestadas.
La página contiene diferentes modeles, demos, imágenes de entrenamiento, preguntas de entrenamiento y todo lo necesario para poder echar a andar el sistema de respuestas inteligente a través de imágenes. Se encuentra en https://visualqa.org/
QuickDraw

Esta página es una divertida collección de dibujos hechos a mano por diferentes ususarios, estos dibujos sirven ara entrenamiento de sistemas de redes neuronales, según la propia página, se tiene una colección de 50 millones de dibujos, que son generados por los jugadores del juego Quick, Draw!, hay que jugarlo, altamente divertido.
De acuerdo a los autores del proyecto, los dibujos se capturaron como vectores con marca de tiempo, etiquetados con metadatos que incluyen lo que se le pidió al jugador que dibujara y en qué país se encontraba el jugador.
La página de este experimento puede verse en:
Y un tutorial generado por los autores de como usar las redes neuronales convolucionales para clasificación de dibujos se puede encontrar en:
https://github.com/tensorflow/docs/blob/master/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
Jeopardy
Este conjunto de datos se encuentra en una entrada de la red social Reddit, y almacena miles de preguntas y respuestas del popular juego Jeopardy, este dataset puede ser utilizado en aplicaciones de PLN para identificar diferentes hechos. La página se encuentra en:
https://www.reddit.com/r/datasets/comments/1uyd0t/200000_jeopardy_questions_in_a_json_file/
Awesome Public Datasets
Este es un repositorio almacenado en GitHub, en el cual diferentes usuarios pueden subir sus contribuciones en datasets, cuenta con conjuntos de datos relacionados a diferentes ramas del conocimiento y temas de interés general y particular.
GitHub – awesomedata/awesome-public-datasets: A topic-centric list of HQ open datasets.
En internet se pueden encontrar miles de estas páginas enfocadas a compartir diferentes datasets para diferentes áreas temáticas, obviamente, aquí solo se han descrito algunas de ellas a modo de ejemplo, sin embargo, si un usuario busca de forma rápida “datasets for machine learning in Knowledge area”, donde “Knowledge area” es el área de interés, el buscador arrojará instantáneamente cientos de ellas, algunas más desarrolladas que otras, pero todas útiles.